This article is an attempt to provide a quick glimpse of
Big Data and Hadoop, two of the top trending words in the field of information
science. Consider this article as more of an introduction to Big Data and
Hadoop for newbies.
To get a hang of these two concepts, we should first know
a few things about Data. The first thing to note is “data” is plural. Its
singular form which is not used very often is “datum”. So data are the
collection of raw facts and figures; which when processed within a context can
be used to derive meaningful information. For instance, the following figures
don’t really convey anything much; till we give it a context and perhaps a
graphical representation.
1
|
2
|
3
|
4
|
1
|
2
|
3
|
4
|
1
|
2
|
3
|
4
|
1500
|
1200
|
1000
|
1395
|
1690
|
800
|
1100
|
1000
|
1555
|
1200
|
1000
|
850
|
Let’s say, in the table above, values in each of the
cells in the first row signify a week number. So ‘1’ corresponds to the first
week of the month, ‘2’ the second week etc. And say, values in the second row
signify expense (in any currency of
choice). So now we can say that we have the data for three months of weekly
expenses which could be represented as shown in the graph below.
 |
| Fig.1 Data Visualization |
Thus, the raw set of data in the table above turns into a
piece of information when we know what each figure means. And we can infer that
every month the expense in the first week is the highest. We could analyze
these data in many different ways to gather many more bits of information. For
instance, what has been the total monthly expense for a month, what is an
average expense per month, which month were the expenses at their lowest and which
is the highest, and with a larger data set one might even gain a deeper insight
that could help one predict what could be expenses in the following months or
weeks etc.
So to reiterate; data is the collection of raw facts and
figures. When these are processed on the backdrop of a context, we derive
meaning which is information. Good, so far?
Now, with the current phase of technological advancement
and the millions and millions of computers at use all over the World, we are
generating an immense amount of data. To form an idea, think about the digital
pictures that are being clicked, shared, uploaded, posted and stored by
billions of people across the globe. The innumerable web pages and posts put on
the web, including this one. The mobile call logs produced across the World by
people calling and talking to one another. The log messages that are generated
when running an application. The emails which are being composed, sent, read or
are being archived. Or the data on temperature and rainfall etc. that are being
collected from across the different patches of the Earth and even space. The
bottom line is we are generating a vast amount of data every second that we
just want to or have to keep. These data are valuable to us, not just from a
sentimental or security or legal or,
logging perspective but also because these could be analyzed to retrieve
amazing bits of intelligence, these could display patterns of behavior, offer
predictive analysis, these digital footprints could help identify an
individualistic or group behavior in terms of buying and selling, on deciding
what’s trending or just predict human behavior in general, this could help with
future designs of applications and machines and what not! These data which are
being produced at such high velocity in such huge volumes with this
mind-boggling variety is called Big Data. Just remember the three V’s that make
an impactful definition of Big Data, that is, Velocity, Volume and Variety. Since
Big Data is pretty complex and unstructured; and we seek a near real-time
analysis and response from it, processing and management of Big Data is
recommended to be done using BASE (Basically
Available Soft state Eventual Consistency) principles of database rather
than the conventional ACID (Atomicity
Consistency Isolation Durability) principle.
So this should bring us to an understanding of the basic concepts
of data and Big Data, in general. Now that we have these data, where should
these be stored? And how should these be stored so that these could be later
retrieved and analyzed conveniently? It is at this point that Big Data
processing tools make their pitch. MongoDB, Cassandra, Aerospike and Hadoop are
just some of the well-known players in the market. Their prerogative is dealing with unstructured
data. Data not organized according to the traditional concept of rows and
columns or normalization. These are No-SQL databases. Some of these are better
known for managing Big Data and some for the capacity to analyze Big Data. Albeit,
Hadoop seems to be gaining a little more momentum in terms of its fan-following
and the accompanying popularity.
Hadoop was created by Doug Cutting. It is an open-source
Apache project. But as it happens with most open-source stuff, two competing
organizations have currently taken over the onus of parenting and the upbringing
of Hadoop, namely Cloudera and HortonWorks. They also provide certifications which are in
pretty good demand in the market. The certification examination from Cloudera
as stated in their official website is mainly MCQ (Multiple-Choice Question) while
the HDP (HortonWorks Development Platform) is more hands-on which is based on
executing certain tasks. More details could be found in their respective
official websites.
Ok, now as promised a quick look into Hadoop. Hadoop is a
big-data analytics tool that is linearly scalable and works on a cluster of
nodes. At a minimum, a cluster might have just one node and at a maximum, it
could span thousands of nodes. The architecture of Hadoop is based on two
concepts: HDFS and MapReduce. But before we plunge into understanding them, we
need to be familiar with a few of the jargon.
1.
Node: A computer-machine
2.
Cluster:
A group of nodes
3.
Commodity Hardware: Machines that aren’t too
expensive to buy or maintain; don’t boast of powerful processing capabilities
4.
Scalability: The ability to cope with increasing
load while maintaining performance and delivery
5.
Horizontal or Linear Scalability: When
scalability is achieved by adding more of commodity hardware that are not very
resource intensive
6.
Vertical Scalability: When scalability is
achieved by adding more powerful machines with greater processing power and
resources
The concept of file systems in Hadoop revolves around the
idea that files should be split into chunks and their storage distributed
across a cluster of nodes with a certain replication factor. Benefits? The
chunking allows parallel processing and the replication promises protection
against data loss. HDFS which stands for Hadoop Distributed File System is just
one of these file system implementations for Hadoop. In simple terms, it is a file system in which
the data or files are partitioned into chunks of size 128MB (default chunk
size) and stored across a number of nodes in the cluster. Each chunk has a
certain number of replication copies called its Replication Factor. It is
ideally three. The HDFS blocks are kept
of size 128MB by default for two reasons- first: this ensures that at any time
an integral number of blocks reside in a disk (typical disk block is of size
512 bytes) and second: with the advent
of storage technologies we have made good progress but still latency due to
disk seek time is still more when compared to reading time; hence large chunks
imply shorter seek times. All the nodes participating in the Hadoop cluster are
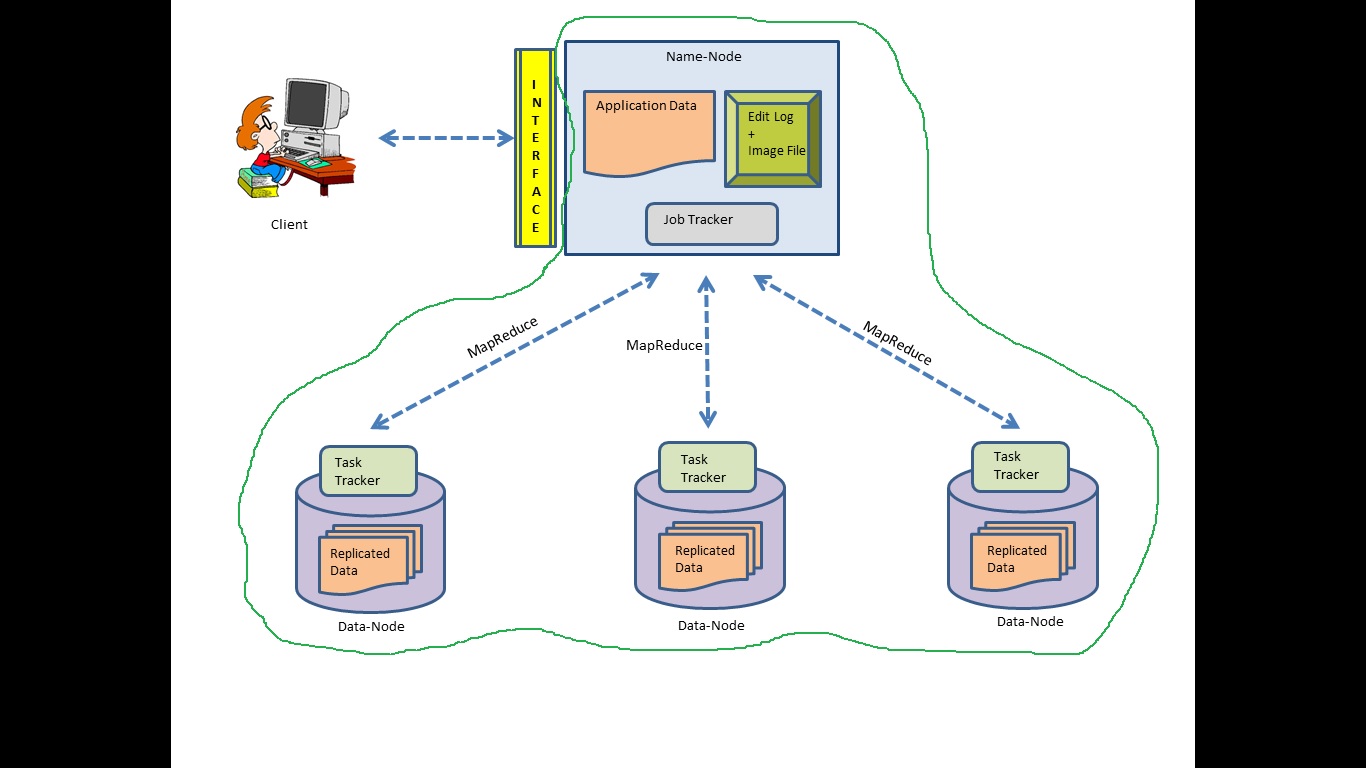
arranged in a master-worker pattern comprising of one name-node (master) and
multiple data-nodes (workers). The name-node holds information on the file-system
tree and the meta-data for all the files and directories in the tree. This
information is locally persisted in the form of two files- edit log and the
namespace image. The data-nodes store and retrieve the chunks of data files
assigned to them by the name-node. Now
in a cluster to keep track of all active nodes, all data-nodes are expected to
send regular heartbeat messages to the name-node together with the list of file
blocks they store. If a data-node is down, the name-node knows in which
alternate data-node to look for a replicated copy of the file block. Thus, data-nodes
are the workhorses of the file-system but the name-node is the brains of the
system. As such, it is of utmost importance to always have the name-node
functioning. Since this could create a precarious situation, hence as of Hadoop
2 there is a provision of two name-nodes; one in active and the other in
standby mode. Now, again there are different approaches through which the data
between the two name-nodes are continually shared to ensure high availability.
Two among these are using NFS Filer or the QJM (Quorum Journal Manager).
Anyways, in this article we just stick to the basics. Will talk about HA (High Availability)
Name-Nodes in another article. Good so far with the concepts of HDFS, file
blocks, name-node and data-node? These form the skeleton of HDFS. Ok, let’s
move onto MapReduce.
MapReduce is the method of executing a given task across
multiple nodes in parallel. Each MapReduce job consists of four phases:
Map->Sort->Shuffle->Reduce. Following terms are of importance when
talking about MapReduce jobs:
1.
JobTracker: the software daemon that resides on
the namenode and assigns map and reduce tasks to other nodes in the cluster.
2.
TaskTracker: the software daemon that resides on
the data-nodes and is responsible for actually running the Map and Reduce tasks
and reporting back the progress to the JobTracker.
3.
Job: a program that can execute Mappers and
Reducers over a dataset
4.
Task: an execution of a single instance of a
Mapper and Reducer over a slice of data
5.
Data locality: it is the practice of ensuring
that a task running on a node works on the data that is closest to that node,
preferably in the same node. To explain a little more; from the above
definition of HDFS we know that data files are split into chunks and stored in
datanodes. The idea of data locality is that the task executing on a node works
on the data stored in that same node. But sometimes, the data in a datanode
might be corrupted or might not be available for some reason. In such a
scenario that task running in that node tries to access the data from the
datanode that is closest to that node. This is done to avoid any cluster bottlenecks
that might arise owing to data transfers between datanodes.
In simple terms, what happens in MapReduce jobs is, the
data to be processed is fed into Mappers that consume the input and generate a set of
key-value pairs. These output from Mappers are then sorted and shuffled and
provided as input to the reduce jobs; which finally crunch the key-value pairs
given to it to generate a final response.
For example, consider a scenario where we have a huge
pile of books. We want a count of all the words that occur in all of these
books and this task is assigned to Hadoop. Hadoop would proceed to do the task
somewhat like this.
The name-node in HDFS, let’s call it ‘master’ splits the
books (application data) into chunks and distributes them across a number of data-nodes;
let’s call them ‘workers’. Thereafter,
the master sends over a bunch mappers and a reducer to each of these workers. This part is taken care of by the sentinels
called JobTrackers and TaskTrackers who oversee the work of the mappers and
reducers. All the mappers must finish their job before any reducer can begin. The
task of the mappers is to simply read the pages from the chunk stored with the
worker, write down each word it encounters in it and a count of 1 against each
word on a page, irrespective of the number of times it encounters the same
word. So the output from each mapper is a bunch of key-value pairs written on
it where each word is a key and all the keys have a value 1. So the output
would be something as shown below:
Apple -> 1
Mango ->1
Person -> 1
Person->1
Apple->1
Person-> 1 etc.
Next, the JobTracker directs the output from all the
mappers to be read by the reducer thereby summing up values against each key.
So continuing with the above sample, the reducer would generate something like
this:
Apple -> 2
Mango->1
Person -> 3
So the output from the reducer gives us the result of the
task. Simple enough to grasp the concept? Hope it is.
Presenting the following picture to offer a quick summary
of the concepts explored here. Most often end-users just interact with a POSIX
(Portable Operating System Interface) with client machines without needing to
know of all the nitty-gritty stuff that Hadoop does.
 |
| Fig.2 Hadop |
No comments:
Post a Comment